A dark spot of Web search engines
Despite the huge success of Web search engines (first and foremost Google), they have two severe limitations for information discovery: they only answer questions that you already know how to ask and they return a context-free answer to your question. This is a epistemological problem: although you will almost always receive search results, you will never know which results may have been interesting, but have never been returned. In military jargon, you can only search for the known unknowns, not the unknown unknowns. Instead, you will receive specific answers to specific questions. People typically only use 2.5 search terms and they do it because search engines cannot answer more interesting search queries.
An analogy
Let me explain this using an analogy from mathematical optimisation. Consider the surface in the below image. In engineering problems, the surface could for example be the length and witdh of an airplane wing and the height and color would be the air resistance associated with it. If we want the wing to have little air resistance, we look where the surface is bluest and read the wing's length and width from the axes and thus have solved the optimisation problem. Because we often do not know how the surface looks like (for that, we would to have tried every possible combination of wing length and width) a frequent approach is to try a few random wing sizes, vary them a little and try to find in which direction the steepest descend is. Then, we can follow it and soon arrive at a bottom.
Conducting a web search is similar, instead of length and width we have a search query, and instead of air resistance we have a measure of match of the search results. But what are the neighbours of a search query? And what if a minor change in search query improves the search results radically? We cannot use the neighbour exploration and following the steepest descend anymore, and are left with randomly guessing search queries. Sometimes Google can help us with a “did you mean…?”, but the trouble with this function is that it rather helps Google give you more search results instead of helping you to find what you were searching for.

PageRank and hyperlinks
In the 2000s, Google was a small revolution, as it was able to list more relevant results by tracking links among the pages using the PageRank algorithm. Meanwhile its competitors envisioned a curated web – a crafted list of links, organised around topics, like baseball, or Renaissance music. By using hyperlinks to rank websites according to their importance, Google relied on the premise that the links had a certain quality – that they were curated. Simultaneously, its outstanding quality of search results made curated link lists obsolete (what was the lat time you found a mostly intact link list?). Google relied on the very foundation it partially displaced.
The entire Web was loosely based on the premise of citation—after all, what is a link but a citation? If he could devise a method to count and qualify each backlink on the Web, as Page puts it “the Web would become a more valuable place.”
John Battelle about Google
Since then, the Web has changed: for example, more people use it, it has become more centralised around few highly popular websites (such as facebook, YouTube and Wikipedia). As displayed in the figure below, website popularity follows a power law, with few websites that are visited extremely often, and a large minority with very few hits. In fact, the most popular 10 websites are responsible for 92 percent of traffic! For comparison, in 1999 you required 119 websites for 32.36%.
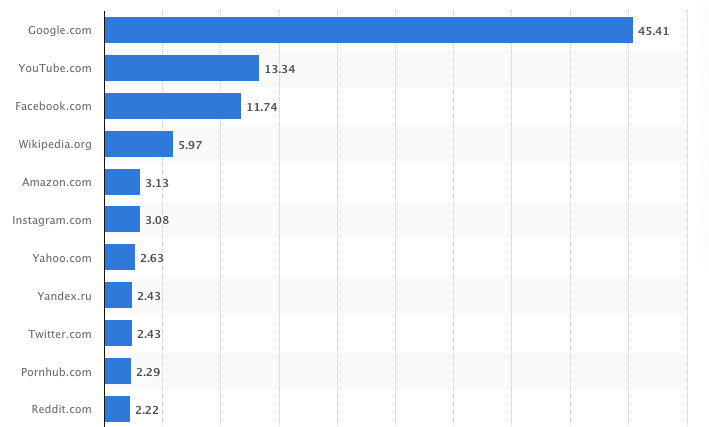
In some sense, centralisation has made search, as offered today, easy: take the most popular 100 websites (e.g. Wikipedia, newspapers,Amazon, Twitter, StackOverflow, YouTube and reddit), forward the search query to them, and rank the results using a similarity mechanism. I claim that this procedure would suffice for a vast majority of search queries submitted by users. Centralisation also limits the value of links, as most of them are directed towards the popular websites. This violates the original idea of PageRank, and leads us to explore only a fraction of the web. In the next section we will see how these reduce the value of the network.
Connected knowledge
A beauty of the Internet is the nonlocality: you can access hundred different websites (or nodes, more generally) about as easy as you can access one website a hundred times. It does not matter whether a website is hosted in the same city as yours or if it is on the other side of the globe (this is also called “referential transperency”). Instead, websites can be connected via links giving raise to some kind of complex landscape in which a websites’ neighbours are not spatial, butsimilar in topic, time, or any other relationship!
The “connectedness” often determines the value of a thing. Metcalfe's law describes the value of a network with n network as proportional to n², and recent studies suggest that a person's intelligence correlates with the complexity of dendrites (connecting structures) in their brain. In a letter sent to Alan Turing a colleague once wrote the following:
I am convinced that the crux of the problem of learning is recognizing relationships and being able to use them.
Christopher Strachey
The nonlocality of the web also has disadvantages: one of them is that you cannot explore the web as you would your neighbourhood, because there is no spatial connectedness. The neighbourhood is given by links, and they are what allows you to explore the web. Exploration is what helps to learn new things, invent things and see connections. With fewer links and less value in them, Google seeked to improve their search by constructing a giant knowledge graph (KG), consisting of connected facts about the World. For example, if you're searching for the film “Top Gun”, Google gives you a list of actors starring in the film because their KG connects the information about the film and the actors in it. In some sense, the decline of link matter in the web (partially due to search itself) is substituted by link matter from the KG. But in contrast to the web, a KG has to be centrally curated and does not emerge from the interactions of millions of users. Also, the KG only represents links from the World, not the ones suggested by the users’ swarm intelligence.
Outlook
As we have grown familiar with Google search, we may conclude that the problem of information discovery on the web is solved (as people thought before Google). I think we're far from it, and two reasons I can think of are because current search queries can only convey a certain amount of information (for example, no context), and because you can search for what you know how to formulate. Even extremely sophisticated systems as Galactiva suffer from this (but it makes efforts for the context part). Compare search queries with accessing an array using an index, where you have to know the index to get something you don't know (and with search engines the index is not just a number, but a high-dimensional query), but for proper information discovery, we would need a more explorative data structure. The 90s model with a link graph was a beginning. Why don't we improve it?
Connection machines
Let me finish with the story of the Connection Machine. It was a supercomputer designed in the 1980s (even Richard Feynman was involved), and envisioned a computer not of a few and fast, but a myriad primitive processors, highly connected with each other. The people behind it envisioned it to emulate the architecture of the human brain (something what is done again with Neuromorphic Computing), and to be able to compute in a highly parallel fashion, with the final goal to attain artificial intelligence. The concept appeared promising, but the Connection Machine was notoriously difficult to program, the company behind it had poor leadership and when military founding ceased, the Connection Machine failed, too.
In a recent interview with Daniel Hillis, the computer's chief architect considered Google an alternative way of attaining intelligence. And now we know, connections were basis for both of them.